Illustration: mining Humanist¶
The following example is meant to show what Orange Textable typically does, without considering (for now) every detail of how it does it.
In a paper reflecting on terminology in the field of Digital Humanities [1], Patrik Svensson compares the evolution of the frequency of expressions Humanities Computing and Digital Humanities over 20 years of archives of the Humanist discussion group. He uses these figures to show that while the former denomination remains prevalent over these two decades, the latter has been quickly gaining ground since the 2000s.
The same experiment can be run with Orange Textable, by building a “visual program” like the one shown on figure 1 below:

Figure 1: Mining Humanist with an Orange Textable schema.
Such a program is called a schema. Its visible part consists of a network of interconnected units called widget instances. Each instance belongs to a type, e.g. URLs, Recode, Segment, and so on. Widgets are the basic blocks with which a variety of text analysis applications can be built. Each corresponds to a fundamental operation, such as “import data from an online source” (URLs) or “replace specific text patterns with others” (Recode) for example. Connections between instances determine the flow of data in the schema, and thus the order in which operations are carried on. Several parallel paths can be constructed, as demonstrated here by the Recode instance, which sends data to Segment as well as Count.
Widget instances can (and indeed must) be individually parameterized in order
to “fine-tune” their operation. For example, double-clicking on the
Recode instance of figure 1 above displays
the interface shown on figure 2 below. What this
particular configuration means is that every line beginning with symbol |
or > (Regex field) should be replaced with an empty string
(Replacement string): in other words, remove those lines that are marked
as being part of a reply to another message. There is a fair amount of
variation between widget interfaces, but regular expressions play an important
role in many of them and Orange Textable’s flexibility owes a lot to them.
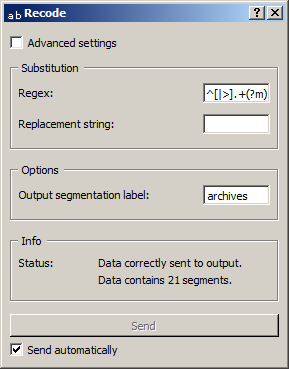
Figure 2: Interface of the Recode widget.
After executing the schema of figure 1 above, the resulting frequencies can be viewed by double-clicking on the Data Table instance, whose interface is shown on figure 3 below. On the whole, these figures lend themselves to the same interpretation as that of Patrik Svensson, but they differ wildly from the frequencies he reports. This might be explained by the fact that, in the present illustration, we have used preprocessed data made available on the Humanist website, or it might be that we have not processed the data exactly like Svensson did. The user can always refer to the Orange Textable schema (including the parameters of each instance) to understand exactly the operations that it performs. [2] In this sense, Orange Textable does not only attempt to make the construction of text analysis programs easier; it aims to make communicating and understanding such programs easier.
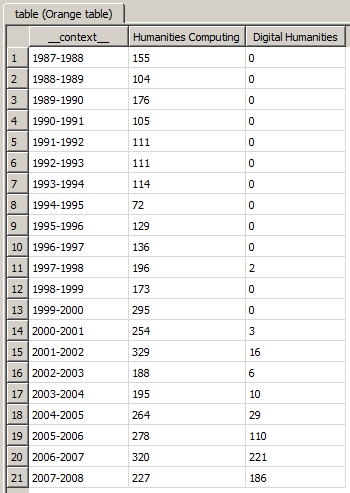
Figure 3: Monitoring the frequency of Humanities Computing vs. Digital Humanities.
| [1] | Svensson, P. (2009). Humanities Computing as Digital Humanities. Digital Humanities Quarterly 3(3). Available here. |
| [2] | The schema can be downloaded from here. Note that two decades of
Humanist archives weigh dozens of megabytes and that retrieving these
data from the Internet can take a few minutes depending on bandwidth.
Please be patient if Orange Textable appears to be stalled when the
schema is being opened. |